FLOPPER
Den aktuelle version af siden er endnu ikke blevet gennemgået af erfarne bidragydere og kan afvige væsentligt fra den
version , der blev gennemgået den 30. december 2021; checks kræver
18 redigeringer .
FLOPS (også flops , flop / s , flops eller flop / s ; et akronym fra engelsk FL oating-point OP erations per sekund , udtales som flops ) er en ikke-systemenhed , der bruges til at måle computerens ydeevne , der viser hvor mange floating point operationer pr. sekund udføres af dette computersystem. Da moderne computere har et højt ydeevneniveau, er de afledte mængder fra flops, dannet ved at bruge SI-præfikser , mere almindelige .
FLOP eller FLOPS
Der er uenighed om, hvorvidt det er tilladt at bruge ordet FLOP fra det engelske. FL -havepunkt OP eration i ental (og varianter såsom flop eller flop ). Nogle mennesker tror, at FLOP (flop) og FLOPS (flop eller flop/s) er synonymer, andre mener, at FLOP blot er antallet af flydende kommaoperationer (f.eks. kræves for at udføre et givet program), og FLOPS er et mål for ydeevne, evnen til at udføre et vist antal flydende kommaoperationer i sekundet.
Flops som et mål for ydeevne
Som de fleste andre ydelsesindikatorer bestemmes denne værdi ved at køre et testprogram på testcomputeren, der løser et problem med et kendt antal operationer og beregner den tid, hvor det blev løst. Det mest populære benchmark i dag er LINPACK benchmarks , specifikt den HPL, der bruges i TOP500 supercomputer -ranglisten .
En af de vigtigste fordele ved at måle ydeevne i flops er, at denne enhed, til nogle grænser, kan fortolkes som en absolut værdi og beregnes teoretisk, mens de fleste andre populære mål er relative og giver dig mulighed for kun at evaluere systemet under test i sammenligning. med en række andre. Denne funktion gør det muligt at bruge forskellige algoritmer til at evaluere resultaterne af arbejdet , samt til at evaluere ydeevnen af computersystemer, der endnu ikke eksisterer eller er under udvikling.
Grænser for anvendelighed
På trods af den tilsyneladende entydighed er flops i virkeligheden et ret dårligt mål for ydeevne, da selve definitionen allerede er tvetydig. Under "floating point operationen" kan en masse forskellige begreber skjules, for ikke at nævne det faktum, at ordlængden af operanderne spiller en væsentlig rolle i disse beregninger , som heller ikke er specificeret nogen steder. Derudover påvirkes flops af mange faktorer, der ikke er direkte relateret til computermodulets ydeevne, såsom båndbredden af kommunikationskanaler med processormiljøet , ydeevnen af hovedhukommelsen og synkroniseringen af cachehukommelsen for forskellige niveauer.
Alt dette fører i sidste ende til, at resultaterne opnået på den samme computer ved hjælp af forskellige programmer kan variere betydeligt; desuden kan der opnås forskellige resultater ved brug af den samme algoritme med hvert nyt forsøg. Til dels løses dette problem ved en aftale om brug af ensartede testprogrammer (samme LINPACK) med gennemsnit af resultaterne, men over tid "vokser computernes muligheder ud af" rammerne for den accepterede test, og den begynder at give kunstigt lave resultater, da den ikke bruger de nyeste funktioner fra computerenheder. Og for nogle systemer kan generelt accepterede tests slet ikke anvendes, hvilket resulterer i, at spørgsmålet om deres ydeevne forbliver åbent.
Så den 24. juni 2006 blev MDGrape-3 supercomputeren , udviklet ved det japanske forskningsinstitut RIKEN ( Yokohama ), med en rekord teoretisk præstation på 1 petaflops , præsenteret for offentligheden . Denne computer er dog ikke en almindelig computer og er tilpasset til at løse en snæver række af specifikke opgaver, mens standard LINPACK-testen ikke kan udføres på den på grund af dens arkitekturs særlige karakter.
Høj ydeevne på specifikke opgaver vises også af grafikprocessorerne på moderne videokort og spilkonsoller . For eksempel er den deklarerede ydeevne for videoprocessoren på PlayStation 3 -spillekonsollen 192 gigaflops [3] , og Xbox 360 's videoaccelerator er 240 gigaflops [3] , hvilket kan sammenlignes med tyve år gamle supercomputere. Så høje tal forklares ved, at ydeevne er angivet på 32-bit tal [4] [5] , mens for supercomputere er ydeevne på 64-bit data normalt angivet [6] [7] . Derudover er disse set-top-bokse og videoprocessorer designet til operationer med tredimensionel grafik, der egner sig godt til parallelisering, dog er disse processorer ikke i stand til at udføre mange generelle opgaver, og deres ydeevne er svær at vurdere med den klassiske LINPACK test [8] og svær at sammenligne med andre systemer.
Toppræstation
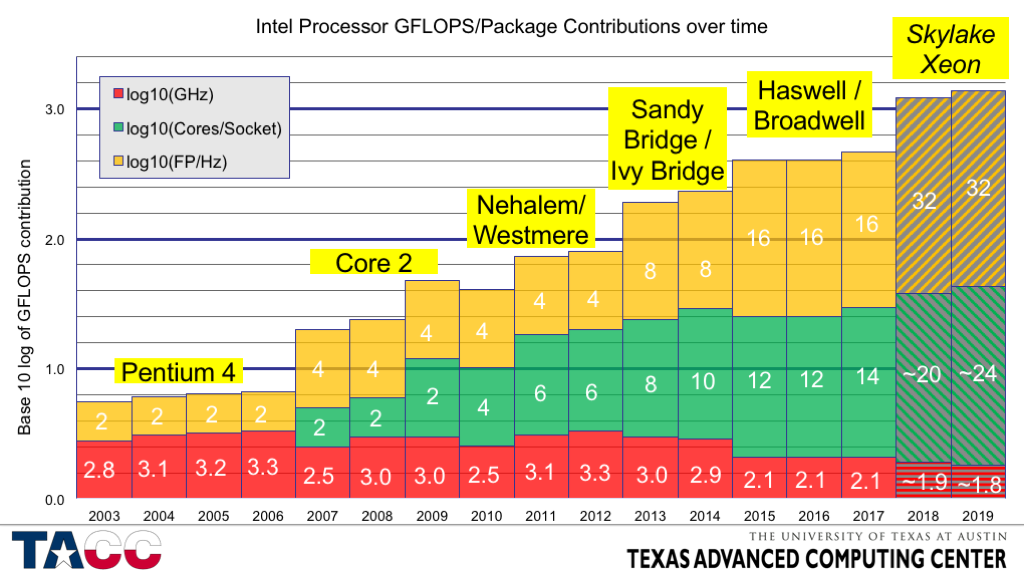
For at beregne det maksimale antal flops for en processor, skal det tages i betragtning, at moderne processorer i hver af deres kerner indeholder flere eksekveringsenheder af hver type (inklusive dem til flydende kommaoperationer), der arbejder parallelt og kan udføre mere end én instruktion pr ur. Denne arkitektoniske funktion kaldes superscalar og dukkede første gang op i CDC 6600 -computeren i 1964. Masseproduktion af computere med superskalær arkitektur begyndte med udgivelsen af Pentium-processoren i 1993. Processoren fra slutningen af 2000'erne, Intel Core 2 , er også superskalær og indeholder 2 64-bit flydende komma-enheder, der kan udføre 2 relaterede operationer (multiplikation og efterfølgende tilføjelse, MAC ) i hver cyklus, hvilket teoretisk giver mulighed for at opnå en maksimal ydeevne på op til 4 operationer pr. 1 cyklus i hver kerne [9] [10] [11] . For en processor med 4 kerner (Core 2 Quad) og arbejder ved en frekvens på 3,5 GHz er den teoretiske ydeevnegrænse 4x4x3,5 = 56 gigaflops, og for en processor med 2 kerner (Core 2 Duo) og opererer ved en frekvens på 3 GHz - 2x4x3 = 24 gigaflops, hvilket er i god overensstemmelse med de praktiske resultater opnået i LINPACK testen.
AMD Phenom 9500 sAM2+ 2,2 GHz: 2200 MHz × 4 kerner × 4⋅10 −3 = 35,2 GFlops
For Core 2 Quad Q6600: 2400 MHz × 4 kerner × 4⋅10 −3 = 38, 4 gigaflops.
Nyere processorer kan udføre op til 8 (f.eks. Sandy og Ivy Bridge , 2011-2012, AVX) eller op til 16 ( Haswell og Broadwell, 2013-2014, AVX2 og FMA3) 64-bit flydende kommaoperationer pr. ur (på hver kerne) [11] . Fremtidige processorer forventes at udføre 32 operationer pr. ur (Intel Xeon Skylake, Xeon *v5, 2015, AVX512) [12]
Sandy og Ivy Bridge med AVX: 8 Flops/ur dobbelt præcision [13] , 16 Flops/ur enkelt præcision
Intel Core i7 2700: / Intel Core i7 3770: 8*4*3900 MHz = 124,8 Gflops peak dobbelt præcision, 16 *4 *3900 = 249,6 Gflops enkelt præcisionstop.
Intel Haswell / Broadwell med AVX2 og FMA3: 16 flops/ur dobbelt præcision [13] ; 32 enkelt præcisions flops/ur
Intel Core i7 4770: 16*4*3900 MHz = 249,6 Gflops peak dobbelt præcision, 32*4*3900 = 499,2 Gflops peak enkelt præcision.
Årsager til udbredt brug
På trods af et stort antal væsentlige mangler, bliver flops fortsat med succes brugt til at evaluere ydeevne baseret på resultaterne af LINPACK-testen. Årsagerne til en sådan popularitet skyldes for det første, at floppet, som nævnt ovenfor, er en absolut værdi. Og for det andet kommer mange opgaver inden for ingeniørvidenskab og videnskabelig praksis i sidste ende ned til at løse systemer med lineære algebraiske ligninger , og LINPACK-testen er baseret på måling af hastigheden af at løse sådanne systemer. Derudover er langt de fleste computere (inklusive supercomputere) bygget efter den klassiske arkitektur ved hjælp af standardprocessorer, hvilket tillader brug af almindeligt accepterede tests med stor pålidelighed.
I forskellige algoritmer kan det udover evnen til at udføre et stort antal matematiske operationer i processorkernen være nødvendigt at overføre store mængder data gennem hukommelsesundersystemet, og deres ydeevne vil være stærkt begrænset på grund af dette, f.eks. , som i niveau 1 og 2 i BLAS-bibliotekerne [11] . Algoritmerne brugt i test som LINPACK (BLAS niveau 3) har dog et højt datagenbrugsforhold, de tager mindre end 1/10 af den samlede tid at overføre data mellem processoren og hukommelsen, og de opnår normalt typisk ydeevne op til 80 -95% af teoretisk maksimum.
Ydeevneoversigt over rigtige systemer
På grund af den høje spredning af LINPACK-testresultater er omtrentlige værdier givet ved hjælp af gennemsnitsindikatorer baseret på information fra forskellige kilder. Ydeevnen for spilkonsoller og distribuerede systemer (som har en snæver specialisering og ikke understøtter LINPACK-testen) er givet til referenceformål i overensstemmelse med de tal, der er angivet af deres udviklere. Mere nøjagtige resultater med specifikke systemparametre kan opnås, for eksempel på The Performance Database Server .
Supercomputere
Uno
Kilo
Mega
Giga
Tera
Peta
- Cray Jaguar ( 2008 ) - 1.059 petaflops
- IBM Roadrunner ( 2008 ) - 1.042 petaflops [16]
- Lomonosov ( 2011 , NIVC MSU) - 1,3 petaflops
- Jaguar Cray XT5-HE ( 2009 ) - 1.759 petaflops
- T-Platform A-Class Cluster (Lomonosov-2, november 2014, forsknings- og udviklingscenter ved Moscow State University) - 1,85 petaflops (i 5 stativer) [17] [18] [19] .
- Tianhe-1A ( 2010 ) - 2,57 petaflops
- Christofari (2019) - 6,7 petaflops ( 75 - node NVIDIA DGX-2- klynge ) [20] [21] [22]
- Fujitsu K computer ( 2011 ) - 8.16-10.51 petaflops [23]
- IBM Sequoia ( 2012 ) - 16.32 petaflops [24]
- Cray Titan (ex. Cray Jaguar ; 2012 ) - >17.59 petaflops [25]
- Chervonenkis (2021) - 21.530 petaflops
- Tianhe-2 ( 2013 ) - 33,86 petaflops [26]
- Sunway TaihuLight (2016) - 93 petaflops
- Summit (2018) - 122,3 petaflops
- Fugaku (2020) - 442,01 petaflops
Exa
Personlige computerprocessorer
Dobbelt præcision maksimal ydeevne [27]
- Zilog Z80 + AMD Am9512 matematisk coprocessor , 3 MHz (1977-1980) ~ 1-2 kflops [28]
- Intel 80486DX/DX2 (1990-1992) - op til 30-50 Mflop/s [29]
- Intel Pentium 75-200 MHz (1996) - op til 75-200 Mflop/s [29] [30]
- Intel Pentium III 450-1133 MHz (1999-2000) - op til 450-1113 Mflop/s [29] [30]
- Intel Pentium III-S (2001) 1 - 1,4 GHz - op til 1 - 1,4 Gflop/s [30]
- MCST Elbrus 2000 300 MHz (2008) - 2,4 Gflop/s
- Intel Atom N270, D150 1,6 GHz (2008-2009) - op til 3,2 Gflop/s [29]
- Intel Pentium 4 2,5-2,8 GHz (2004) - op til 5 - 5,6 Gflop/s [29]
- MCST Elbrus-2C+ 500 MHz, 2 kerner (2011) - 8 Gflop/s
- AMD Athlon 64 X2 4200+ 2,2 GHz, 2 kerner ( 2006 ) - 8,8 Gflops/s
- Intel Core 2 Duo E6600 2,4 GHz 2 core (2006) - 19,2 Gflop/s
- MCST Elbrus-4S (1891VM8Ya, Elbrus v.3) 800 MHz, 4 kerner (2014) — 25 Gflop/s [31]
- Intel Core i3 -2350M 2,3 GHz 2 kerne (2011) - 36,8 Gflop/s
- Intel Core 2 Quad Q8300 2,5 GHz 4 core (2008) - 40 Gflop/s
- AMD Athlon II X4 640 3,0 GHz 4 Core ( 2010 ) - 48 Gflop/s
- Intel Core i7-975 XE ( Nehalem ) 3,33 GHz 4 core (2009) - 53,3 Gflop/s
- AMD Phenom II X4 965 BE 3,4 GHz 4 core ( 2009 ) - 54,4 Gflop/s
- AMD Phenom II X6 1100T 3,3 GHz 6 Core (2010) - 79,2 Gflop/s
- Intel Core i5 -2500K ( Sandy Bridge ), 3,3 GHz, 4 kerner (2011) - 105,6 Gflop/s
- MCST Elbrus-8S (Elbrus v.4) 1,3 GHz, 8 kerner (2016) — 125 Gflop/s [32] [33]
- AMD FX-8350 4 GHz 8 kerner (2012) - 128 Gflop/s [34]
- Intel Core i7 -4930K ( Ivy Bridge ) 3,4 GHz 6 kerner (2013) - 163 GFlops/s
- Loongson-3B1500 ( MIPS64 ), 1,5 GHz, 8 kerner (2016) - op til 192 GFlop/s [35]
- AMD Ryzen 7 1700X ( Zen ) 3,4 GHz 8-core (2017) [36] - 217 GFlops [37]
- MCST Elbrus-8SV (Elbrus v.5) 1,5 GHz, 8 kerner (2020 - plan) [38] - 288 Gflop/s [39] [40]
- IBM Power8 4,4 GHz, 12 kerner (2013), 290 Gflop/s
- Intel Core i7-5960X (Extreme Edition Haswell -E), 3,0 GHz, 8 kerner (2014) - 384 Gflop/s (op til 350 Gflop/s opnåelige i praksis [41] )
- Intel Core i9-9900k ( Coffee Lake ), 3,6 GHz, 8 kerner (2018) [42] - 460 Gflops [43]
- AMD Ryzen 7 3700X ( Zen 2 ), 3,6 GHz, 8 kerner (2019) [44] - 460 GFlops [43]
- MCST Elbrus-12S 2 GHz, 12 kerner (2020 - plan) - 576 Gflop/s
- MCST Elbrus-16S 2 GHz, 16 kerner (2021 - plan) - 768 Gflop/s [45] .
- AMD Ryzen 9 3950X ( Zen 2 ) 3,5 GHz 16 kerner (2019) [46] - 896 GFlops/s [47]
- AMD EPYC 7H12 ( Zen 2 ), 3,3 GHz, 64 kerner (2019) [48] - 4,2 teraflops [49]
Antal FLOP'er pr. ur for forskellige arkitekturer
For et antal processormikroarkitekturer er det maksimale antal flydende operationer, der udføres pr. ur på én kerne, kendt. Listen nedenfor viser mikroarkitekturnavne, ikke processorfamilier.
(enkelt) - enkelt præcision; (dobbelt) - dobbelt præcision [50]
- Intel P5 & P6 (ingen ISE'er) + Pentium Pro & Pentium II = 1 (enkelt); 1 (dobbelt)
- P6 (kun Pentium III) = 4 (enkelt); 1 (dobbelt)
- Bonnell ( Atom ) = 4( Enkelt ); 1 ( dobbelt )
- NetBurst = 4 (enkelt); 2 (dobbelt)
- Pentium M & Enhanced Pentium M = 4 (enkelt); 2 (dobbelt)
- Core, Penryn, Nehalem & Westmere = 8 (enkelt); 4 (dobbelt)
- Sandy Bridge & Ivy Bridge = 16 (enkelt); 8 (dobbelt)
- Haswell, Broadwell, Skylake, Kaby Lake & Coffee Lake = 32 (enkelt); 16 (dobbelt)
- Skylake-X, Skylake-SP, Cascade Lake-X (Xeon Gold & Platinum) = 64 (enkelt); 32 (dobbelt) [51] [52]
- Bonnell, Saltwell, Silvermont & Airmont = 6 (enkelt); 1,5 (dobbelt)
- MIC ("Knights Corner" Xeon Phi) = 32 (enkelt); 16 (dobbelt)
- MIC ("Knights Landing" Xeon Phi) = 64 (enkelt); 32 (dobbelt) [51]
- AMD K5 & K6 = 0,5 (enkelt); 0,5 (dobbelt)
- K6-2 & K6-III = 4 (enkelt); 0,5 (dobbelt)
- K7 = 4 (enkelt); ? (dobbelt)
- K8 = 4 (enkelt); 2 (dobbelt)
- K10/Stjerner = 8 (enkelt); 4 (dobbelt)
- Husky = 8 (enkelt); 4 (dobbelt)
- Bulldozer, pælemaskine, damptromle og gravemaskine (Total pr. par kerner - modul [53] ) = 16 (enkelt); 8 (dobbelt)
- Bobcat = 4 (enkelt); 1,5 (dobbelt)
- Jaguar, Puma og Puma+ = 8 (enkelt); 3 (dobbelt)
- Zen, Zen+ = 16 (enkelt); 8 (dobbelt)
- Zen 2 = 32 (enkelt); 16 (dobbelt)
- MCST Elbrus 2000 (E2K) = 16 (enkelt); 8 (dobbelt) [54] [55]
- Elbrus version 3 = 16 (enkelt); 8 (dobbelt)
- Elbrus version 4 = 24 (enkelt); 12 (dobbelt) [56] [57]
- Elbrus version 5 = 48 (enkelt); 24 (dobbelt) [58] [59]
Lommecomputerprocessorer
- PDA baseret på Samsung S3C2440 400 MHz processor ( ARM9 arkitektur ) - 1,3 megaflops
- Intel XScale PXA270 520 MHz - 1,6 megaflops
- Intel XScale PXA270 624 MHz - 2 megaflops
- Samsung Exynos 4210 2x1600 MHz - 84 megaflops
- Apple A6 - 645 megaflops (LINPACK-estimat)
- Apple A7 - 833 megaflops (LINPACK estimat) [60]
- Apple A8 - 1,4 gigaflops [61]
- Apple A10 - 365 gigaflops (fp32), 91 gigaflops (fp64) [62]
- Apple A14 - 824 gigaflops (fp32), 206 gigaflops (fp64) [62]
Distribuerede systemer
- Bitcoin - har en betydelig mængde specialiserede computerressourcer, men løser kun heltalsproblemer (beregner SHA256-hashsummen ) . Næsten alle regnemaskiner er implementeret i form af specielle brugerdefinerede mikrokredsløb (ASIC), som ikke er teknisk i stand til at udføre beregninger på flydende kommatal. Derfor er det i øjeblikket forkert at evaluere Bitcoin-netværket ved hjælp af flops. [63] [64] [65] Tidligere, indtil 2011, blev der kun brugt CPU'er og GPU'er i netværket , som kan håndtere både heltal- og flydende data, og flop-estimatet blev opnået fra hash/s-metrikken ved hjælp af en empirisk faktor på 12, 7 tusind. [66] [67] For eksempel, fra april 2011, blev netværkets kraft estimeret ved denne metode til omkring 8 petaflops. [68]
- Folding@home er over 2,6 exaflops pr. 23. april 2020, hvilket gør det til det mest kraftfulde og største distribuerede computerprojekt i verden.
- BOINC - over 41,5 petaflops i marts 2020 [69]
- SETI@home - 0,66 petaflops (for 2013) [70]
- Einstein@Home — mere end 5,2 petaflops i marts 2020 [71]
- Rosetta@home - mere end 1,4 petaflops fra marts 2020.
Spilkonsoller
Flydende komma-operationer på 32-bit data specificeret
- Sega Dreamcast - 1,4 gigaflops
- Nintendo GameCube - 1,9 gigaflops ( CPU ), 8,6 gigaflops ( ATI-AMD "Flipper" GPU ) [72]
- Sony PlayStation Portable - 2,6 gigaflops [73]
- Nintendo Wii - 2,9 gigaflops (CPU) [74]
- Microsoft Xbox - 2.9 gigaflops (Intel Pentium III 733 Mhz CPU), 80.0 gigaflops (Nvidia XGPU 233 Mhz GPU) [72]
- Sony PlayStation 2 - 6,2 gigaflops
- Microsoft Xbox 360 - 115.2 gigaflops (IBM Xenon CPU ), 240 gigaflops (ATI-AMD Xenos GPU )
- Sony PlayStation 3 - 230,4 gigaflops enkelt præcision og op til +15 gigaflops dobbelt præcision (CPU Cell BE ) [75] [76]
- Nintendo Wii U - 352 gigaflops (GPU, formentlig) [77]
- Sony PlayStation 3 - 400,4 gigaflops (GFlops) RSX Nvidia G70 550 MHz [3]
- Microsoft Xbox One - 1.23 teraflops (GPU) [78]
- Sony PlayStation 4 (AMD Radeon GPU) - 1,84 teraflops [79]
- Sony PlayStation® 4 Pro - 4.20 TFLOPS (AMD Radeon GPU) [80]
- Microsoft Xbox One X - 6 teraflops (GPU)
- Sony PlayStation 5 ( Radeon Navi GPU , med RDNA2- arkitektur) - 10,3 teraflops [81]
- Microsoft Xbox Series X - 12 teraflops (GPU) [82]
GPU'er
Teoretisk ydeevne (FMA; gigaflops):
Mand og lommeregner
Det er ikke tilfældigt, at en lommeregner falder ind under samme kategori som en person, for selvom det er en elektronisk enhed, der indeholder en processor, hukommelse og input-output-enheder, er dens funktionsmåde fundamentalt anderledes end en computers. Lommeregneren udfører den ene operation efter den anden med den hastighed, hvormed de bliver anmodet af den menneskelige operatør. Den tid, der går mellem operationerne, er bestemt af menneskelige evner og overstiger væsentligt den tid, der bruges direkte på beregninger. Vi kan sige, at den gennemsnitlige ydeevne for de enkleste konventionelle lommeregnere er omkring 10 flops eller mere.
Hvis du ikke tager undtagelsestilfælde (se fænomenal tæller ), så udfører en almindelig person, der kun bruger en pen og papir, floating point-operationer meget langsomt og ofte med en stor fejl, og taler således om en persons ydeevne som en computerenhed , skal man bruge sådanne enheder, som milliflops og endda mikroflops.
Se også
Noter
- ↑ Nyt twist Arkiveret 11. september 2013 på Wayback Machine Byrd Kiwi , PC World, nr. 07, 2012: "Hvis den nuværende fremskridtshastighed for supercomputere fortsætter, så vil den næste ydeevnemilepæl være 1 exaflops eller en kvintillion (10) ^18) operationer per sekund, der forventes at blive nået i 2019 ... det menes, at en computer med en ydeevne på én zettaflops (10^21 eller sextillion operationer) kan bygges omkring 2030. Desuden er vilkår allerede i vente for den næste computergrænse - yottaflops (10^ 24) og xeraflops (10^27)."
- ↑ Peta, exa, zetta, yotta... Arkiveret 3. december 2013 på Wayback Machine Byrd Kiwi , Computerra, Dato: 16. juli 2008: "Denne grænse bør følges af zettaflops (10^21), yottaflops (10^ 24 ) og xeraflops (10^27)."
- ↑ 1 2 3 PLAYSTATION 3のグラフィックスエンジン RSX . Dato for adgang: 30. december 2016. Arkiveret fra originalen 17. september 2016. (ubestemt)
- ↑ http://ixbtlabs.com/articles3/video/rv670-part1-page1.html Arkiveret 13. januar 2010 på Wayback Machine floating-point ALU'er .. understøttelse af FP32-præcision
- ↑ Arkiveret kopi (link ikke tilgængeligt) . Hentet 17. august 2009. Arkiveret fra originalen 5. juli 2009. (ubestemt) disse er enkeltpræcision GPU-spidsværdier
- ↑ Arkiveret kopi (link ikke tilgængeligt) . Hentet 17. august 2009. Arkiveret fra originalen 15. oktober 2009. (ubestemt) HPL er en softwarepakke, der løser et tæt lineært system i dobbelt præcision (64 bit)
- ↑ [1] Arkiveret 1. september 2009 på Wayback Machine [2] Arkiveret 1. september 2009 på Wayback Machine HPL FAQ-indgange for præcision
- ↑ Udnyttelse af ydeevnen af 32 bit FP Arithmetic til at opnå 64 bit nøjagtighed (genoptagelse af iterativ raffinement for lineære systemer) Arkiveret 4. december 2008 på Wayback Machine
- ↑ SSE, SSE2 & SSE3 maks. gennemløb: 4 flop/cyklus . Hentet 28. september 2017. Arkiveret fra originalen 16. marts 2012. (ubestemt)
- ↑ Nettoresultatet er, at du nu kan behandle 2 DP-tillæg og 2 DP-multiplikationer pr. ur, eller 4 FLOPS pr. cyklus. (DP) . Dato for adgang: 20. juli 2010. Arkiveret fra originalen den 24. maj 2010. (ubestemt)
- ↑ 1 2 3 Jack Dongarra. Adaptive Linear Solvers og Eigensolvers (engelsk) (ikke tilgængeligt link) . Argonne-træningsprogram om databehandling i ekstrem skala . Argonne National Laboratory (13. august 2014). Hentet 13. april 2015. Arkiveret fra originalen 24. april 2016.
- ↑ Jack Dongarra, Peak Performance - Per Core Arkiveret 22. december 2015 på Wayback Machine / Et kig på High Performance Computing, 2015-10-15
- ↑ 1 2 http://sites.utexas.edu/jdm4372/2016/11/22/sc16-invited-talk-memory-bandwidth-and-system-balance-in-hpc-systems/ Arkiveret 2. februar 2017 på Wayback Maskine http://sites.utexas.edu/jdm4372/files/2016/11/Slide20.png Arkiveret 2. februar 2017 på Wayback Machine
- ↑ Computerkraft: fra den første pc til den moderne supercomputer . Hentet 19. marts 2020. Arkiveret fra originalen 19. marts 2020. (ubestemt)
- ↑ The Emergence of Numerical Weather Prediction: fra Richardson til ENIAC Arkiveret 2. december 2013 på Wayback Machine , 2011
- ↑ IBM har skabt den mest kraftfulde supercomputer i verden _ _
- ↑ T-PLATFORM A-KLASSE CLUSTER, XEON E5-2697V3 14C 2,6GHZ, INFINIBAND FDR, NVIDIA K40M Arkiveret 29. november 2014 på Wayback Machine // Top 500, november 2014
- ↑ Ny vurdering af TOP500 supercomputere Arkivkopi af 21. november 2014 på Wayback Machine // Computerra, 18. november 2014: "... en A-klasse klynge skabt af T-Platforms for Research Computing Center ved Moscow State University. "
- ↑ Den nye supercomputer på MSU kom ind i Top500 Archival kopi dateret 17. november 2016 på Wayback Machine // Data Center World, Open Systems, 11/19/2014: “Den nye MSU supercomputer har kun fem computerracks med 1280 noder baseret på 14-core Intel Xeon E5-processorer -2697 v3 og NVIDIA Tesla K40 acceleratorer med en samlet RAM-kapacitet på mere end 80TB. … Hvert rack på en supercomputer bruger omkring 130 kW."
- ↑ Christofari - NVIDIA DGX-2, Xeon Platinum 8168 24C 2.7GHz, Mellanox InfiniBand EDR, NVIDIA Tesla V100 Arkiveret 3. januar 2020 på Wayback Machine - top500, 2019-11
- ↑ Videopræsentation af Christofari-supercomputeren . Sbercloud. Hentet 27. december 2019. Arkiveret fra originalen 17. december 2019. (Russisk)
- ↑ Sberbank skabte den mest kraftfulde supercomputer i Rusland . RIA Novosti (20191108T1123+0300Z). Dato for adgang: 8. november 2019. Arkiveret fra originalen 8. november 2019. (Russisk)
- ↑ Japansk supercomputer klarer sig bedre end kinesisk arkivkopi dateret 5. november 2011 på Wayback Machine (russisk)
- ↑ Lawrence Livermore's Sequoia Supercomputer Towers over resten i seneste TOP500-liste Arkiveret 11. september 2017 på Wayback Machine , TOP500 News Team | 16. juli 2012
- ↑ Agam Shah (IDG News), Titan supercomputer rammer 20 petaflops af processorkraft Arkiveret 3. juli 2017 på Wayback Machine // PCWorld, Computers, 29. oktober 2012
- ↑ Lovende funktioner i Tianhe-2 Arkiveret 28. november 2014 på Wayback Machine // Open Systems, nr. 08, 2013
- ↑ Enkeltpræcisionsydelsen for de fleste processorer er nøjagtig 2 gange højere end de angivne værdier.
- ↑ Fra 1200 til 4900 processorcyklusser for at udføre 1 dobbelt præcisionsinstruktion afhængigt af deres type, enkelt præcisionsoperationer blev udført cirka 10 gange hurtigere: https://datasheetspdf.com/pdf/1344616/AMD/Am9512/1 Arkiveret kopi fra 26. december , 2019 på Wayback Machine (side 4)
- ↑ 1 2 3 4 5 Ryan Crierie. http://www.alternatewars.com/BBOW/Computing/Computing_Power.htm (engelsk) . Alternative krige (13. marts 2014). Dato for adgang: 23. januar 2015. Arkiveret fra originalen 23. januar 2015.
- ↑ 1 2 3 Jack J. Dongarra. Ydeevne for forskellige computere, der bruger standardsoftware til lineære ligninger ( 15. juni 2014). Hentet 23. januar 2015. Arkiveret fra originalen 17. april 2015.
- ↑ Elbrus-4C mikroprocessor (utilgængeligt link) . MCST. Hentet 28. juni 2015. Arkiveret fra originalen 4. juni 2014. (ubestemt)
- ↑ Central processor "Elbrus-8S" (TVGI.431281.016) . JSC "MCST" . Hentet 16. december 2017. Arkiveret fra originalen 30. marts 2018. (ubestemt)
- ↑ Seks 64-bit FMAC - blokke pr. kerne: 8 x 1,3 x 6 x 2 = 124,8 GFlops/s dobbelt præcision topydelse
- ↑ To 128-bit FMAC - blokke i hvert modul, der kombinerer et par kerner, der opererer ved en frekvens på 4 GHz: 4x4x2x2x128/64 = 128 GFlops/s topydelse i dobbeltpræcisionsberegninger
- ↑ Alex Voica. Nye MIPS64-baserede Loongson-processorer bryder ydeevnebarrieren (engelsk) (downlink) (3. september 2015). Hentet 4. februar 2017. Arkiveret fra originalen 5. februar 2017.
- ↑ Arkiveret kopi . Hentet 26. december 2019. Arkiveret fra originalen 27. juni 2019. (ubestemt)
- ↑ To 128-bit FMAC - blokke pr. kerne: 8 x 3,4 x 2 x 2 x 128/64 = 217,6 Gflops/s dobbeltpræcision topydelse
- ↑ Mikroprocessor "Elbrus-8SV" (TVGI.431281.023) . JSC "MCST" . Dato for adgang: 16. december 2017. Arkiveret fra originalen 27. december 2019. (ubestemt)
- ↑ Første Elbrus-8SV . Hentet 23. september 2017. Arkiveret fra originalen 23. september 2017. (ubestemt)
- ↑ Seks 128-bit FMAC - blokke pr. kerne: 8 x 1,5 x 6 x 2 x 128/64 = 288 Gflops med dobbelt præcisions -spidsydelse
- ↑ Linpack-ydelse Haswell E (Core i7 5960X og 5930K) - Puget brugerdefinerede computere . Dato for adgang: 15. januar 2015. Arkiveret fra originalen 27. marts 2015. (ubestemt)
- ↑ Intel® Core™ i9-9900K-processor (16 MB cache, op til 5,00 GHz) Produktspecifikationer . Hentet 26. december 2019. Arkiveret fra originalen 5. marts 2021. (ubestemt)
- ↑ 1 2 To 256-bit FMAC - blokke pr. kerne: 8 x 3,6 x 2 x 2 x 256/64 = 460 GFlop/s
- ↑ Arkiveret kopi . Hentet 26. december 2019. Arkiveret fra originalen 27. juni 2019. (ubestemt)
- ↑ Elbrus 16C mikroprocessor (første tekniske prøver modtaget) . Hentet 30. januar 2020. Arkiveret fra originalen 4. januar 2020. (ubestemt)
- ↑ Arkiveret kopi . Hentet 26. december 2019. Arkiveret fra originalen 24. juli 2019. (ubestemt)
- ↑ To 256-bit FMAC - blokke pr. kerne: 16 x 3,5 x 2 x 2 x 256/64 = 896 GFlops/s
- ↑ Specifikationer for AMD EPYC 7H12 . techpowerup . Dato for adgang: 10. oktober 2021.
- ↑ AMD afslører sin mest kraftfulde 64-core processor . iXBT.com . Hentet 10. oktober 2021. Arkiveret fra originalen 10. oktober 2021. (Russisk)
- ↑ arkitektur - Sådan beregnes enkeltpræcisionsdata og dobbeltpræcisionsdataspidsydelse for Intel(R) Core™ i7-3770 CPU - Stack Overflow . Hentet 15. oktober 2017. Arkiveret fra originalen 22. oktober 2015. (ubestemt)
- ↑ 1 2 Oversigt over Intel® Advanced Vector Extensions 512 (Intel® AVX-512) . Hentet 24. december 2019. Arkiveret fra originalen 24. december 2019. (ubestemt)
- ↑ Det angivne antal instruktioner pr. cyklus kan kun udføres af de ældre repræsentanter for disse arkitekturer, solgt under markedsføringsnavnene Xeon Platinum og Xeon Gold startende fra 6xxx-serien, som har to 512-bit FMAC-blokke i hver kerne til at udføre AVX -512 instruktioner. For alle juniormodeller: Xeon Bronze, Xeon Silver og Xeon Gold 5ххх, er en af FMAC-blokkene deaktiveret, og derfor reduceres den maksimale udførelseshastighed af floating point-instruktioner med 2 gange.
- ↑ Floating Point Processing Unit (FPU) deles pr. modul - et par processorkerner. Når flydende operationer udføres samtidigt på begge kerner, deles det mellem dem.
- ↑ Kort beskrivelse af Elbrus/Elbrus arkitektur . Hentet 26. december 2019. Arkiveret fra originalen 11. juni 2017. (ubestemt)
- ↑ Denne mikroarkitektur tilhører VLIW -klassen og har 6 parallelle kanaler til udførelse af instruktioner, hvoraf 4 er udstyret med 64-bit flydende komma-enheder af FMAC -typen .
- ↑ Elbrus-8S (TVGI.431281.016) / Elbrus-8S1 (TVGI.431281.025) - central processor 1891VM10Ya / 1891VM028 / MCST . Hentet 16. december 2017. Arkiveret fra originalen 30. marts 2018. (ubestemt)
- ↑ I 4. generation af arkitekturen er 64-bit FMAC-blokke allerede tilgængelige på alle 6 kanaler for instruktionsudførelse.
- ↑ Elbrus-8SV (TVGI.431281.023) - central processor 1891VM12YA / MCST . Dato for adgang: 16. december 2017. Arkiveret fra originalen 27. december 2019. (ubestemt)
- ↑ I 5. generation af arkitekturen blev bitdybden af alle FMAC-blokke øget fra 64 til 128.
- ↑ Sergei Uvarov. Detaljeret gennemgang og test af Apple iPhone 5s . IXBT.com (23. september 2013). Arkiveret fra originalen den 2. oktober 2013. (ubestemt)
- ↑ Apple A8 SoC - NotebookCheck.net Tech . Hentet 15. januar 2015. Arkiveret fra originalen 20. december 2014. (ubestemt)
- ↑ 1 2 Apple A10 - Sammenlignende specifikationer og CPU-benchmarks . Hentet 22. januar 2022. Arkiveret fra originalen 22. januar 2022. (ubestemt)
- ↑ [3] Arkiveret 30. august 2017 på Wayback Machine // Gizmodo, 5/13/13: "Fordi Bitcoin-minearbejdere faktisk laver en enklere form for matematik (heltalsoperationer), skal du lave en lille (rodet) konvertering for at få til FLOPS. .. nye ASIC-minearbejdere - maskiner .. laver ikke andet end at mine Bitcoins - kan ikke engang udføre andre former for operationer, de er helt udeladt af totalen."
- ↑ [4] Arkiveret 3. december 2013 på Wayback Machine // SlashGear, 13. maj 2013: "Bitcoin-minedrift fungerer teknisk set ikke ved hjælp af FLOPS, men snarere heltalsberegninger, så tallene konverteres til FLOPS for en konvertering, som de fleste folk kan forstå mere. Da konverteringsprocessen er en smule mærkelig, har det ført til, at nogle eksperter har gjort sig skyldige i minetallene."
- ↑ [5] Arkiveret 27. november 2013 på Wayback Machine // ExtremeTech: "Da Bitcoin-minedrift ikke er afhængig af floating-point-operationer, er disse estimater baseret på alternativomkostninger. Nu hvor vi har hardware med applikationsspecifikke integrerede kredsløb (ASIC'er) designet fra bunden til ikke at gøre andet end at mine Bitcoins, bliver disse estimater endnu mere uklare."
- ↑ [6] Arkiveret 3. december 2013 på Wayback Machine // CoinDesk : "To, estimaterne brugt til at konvertere hashes til flops (som resulterer i omkring 12.700 flops pr. hash) dateres til 2011, før ASIC-enheder blev normen for bitcoin-mining. ASIC'er håndterer slet ikke flops, så den nuværende sammenligning er meget grov."
- ↑ [7] Arkiveret 3. december 2013 på Wayback Machine // VR-Zone: "En konverteringsrate på 1 hash = 12,7K FLOPS bruges til at bestemme netværksbidragets generelle hastighed. Estimatet blev oprettet i 2011, før oprettelsen af ASIC-hardware udelukkende designet til bitcoin-minedrift. ASIC bruger slet ikke flydende komma-operationer... Derfor har estimatet ikke nogen reel betydning for sådan hardware."
- ↑ Bitcoin Watch , arkiveret 2011-04-08: "Network Hashrate TFLOP/s 8007"
- ↑ BOINC Arkiveret 19. september 2010.
- ↑ BOINCstats:SETI@home Arkiveret fra originalen den 3. maj 2012.
- ↑ BOINCstats:Einstein@Home . Hentet 16. april 2012. Arkiveret fra originalen 21. februar 2012. (ubestemt)
- ↑ 12 Konsol Specifikationer . Hentet 7. december 2017. Arkiveret fra originalen 10. april 2021. (ubestemt)
- ↑ PSP Specs Revealed Behandlingshastighed, polygonhastighed og meget mere. Arkiveret 28. juli 2009 på Wayback Machine // IGN Entertainment, 2003. "PSP CPU CORE...FPU, VFPU (Vector Unit) @ 2.6GFlops"
- ↑ Opdatering: Hvor mange FLOPS er der i spilkonsoller? Arkiveret 9. november 2010 på Wayback Machine // TG Daily, 26. maj 2008
- ↑ Cell Broadband Engine Architecture og dens første implementering . IBM developerWorks (29. november 2005). Hentet 6. april 2006. Arkiveret fra originalen 24. januar 2009. (ubestemt)
- ↑ Udnyttelse af ydeevnen af 32 bit flydende kommaaritmetik til at opnå 64 bit nøjagtighed . University of Tennessee (31. juli 2005). Hentet 11. februar 2011. Arkiveret fra originalen 18. marts 2011. (ubestemt)
- ↑ Philip Wong . Xbox One vs. PS4 vs. Wii U [opdatering ] (engelsk) , CNET Asia, Games & Gear (22. maj 2013). Arkiveret fra originalen den 3. december 2013. Hentet 29. november 2013.
- ↑ Anand Lal Shimpi. Xbox One: Hardwareanalyse og sammenligning med PlayStation 4 (engelsk) . Anandtech (22. maj 2013). Arkiveret fra originalen den 2. oktober 2013.
- ↑ PS4-specifikation (link ikke tilgængeligt) . Hentet 22. juni 2013. Arkiveret fra originalen 20. juni 2013. (ubestemt)
- ↑ Specifikationer . Playstation. Hentet 14. december 2018. Arkiveret fra originalen 4. maj 2019. (Russisk)
- ↑ Sony afslører nye PlayStation-specifikationer . RIA Novosti (20200318T2333+0300). Hentet 20. marts 2020. Arkiveret fra originalen 20. marts 2020. (Russisk)
- ↑ Hvad du kan forvente af den næste generation af spil . Xbox Wire (24. februar 2020). Hentet 24. februar 2020. Arkiveret fra originalen 24. februar 2020.
- ↑ NVIDIA GeForce RTX 2080 Ti-specifikationer | TechPowerUp GPU-database
- ↑ 1 2 3 4 Sammenligningstabeller for AMD (ATI) Radeon-grafikkort . Hentet 24. februar 2012. Arkiveret fra originalen 28. februar 2012. (ubestemt)
Links
{kind=link}
{kind=link}